What every developer should know about TCP
Why do you need to place your servers geographically close to your users? One of the reasons is to achieve lower latencies. That makes a lot of sense when you are sending short bursts of data that should be delivered as quickly as possible. But what about large files, such as videos? Surely there is a latency penalty for receiving the first byte, but shouldn’t it be smooth sailing after that?
A common misconception when sending data over TCP, like with HTTP, is that bandwidth is independent of latency. But, with TCP, bandwidth is a function of latency and time. Let’s see how.
Handshake
Before a client can start sending data to a server, it needs to perform a handshake for TCP and another one for TLS.
TCP uses a three-way handshake to create a new connection.
- The sender picks a randomly generated sequence number “x” and sends a SYN packet to the receiver.
- The receiver increments “x,” chooses a randomly generated sequence number “y” and sends back a SYN/ACK packet.
- The sender increments both sequence numbers and replies with an ACK packet and the first bytes of application data.
The sequence numbers are used by TCP to ensure the data is delivered in order and without holes.
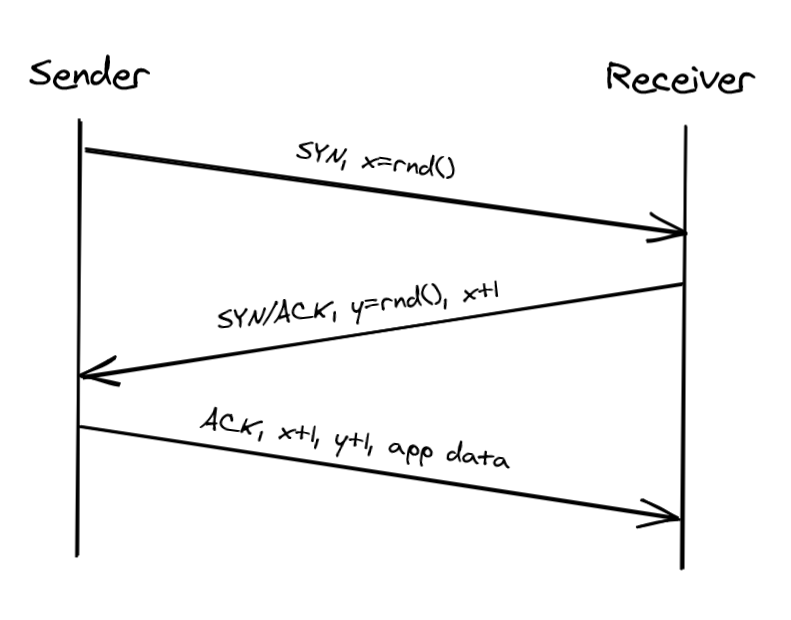
The handshake introduces a full round-trip, which depends on the latency of the underlying network. The TLS handshake also requires up to two round trips. Until the TLS connection is open, no application data can be sent, which means your bandwidth is for all intent and purposes zero until then. The lower the round trip time is, the faster the connection can be established.
Flow Control
Flow control is a backoff mechanism implemented to prevent the sender from overwhelming the receiver.
The receiver stores incoming TCP packets waiting to be processed by the application into a receive buffer.
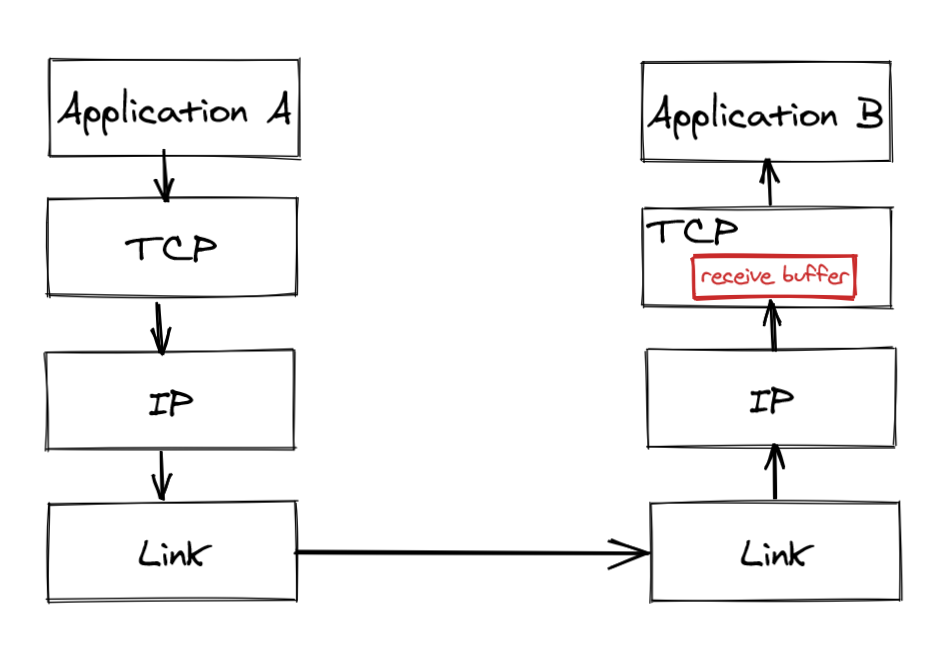
The receiver also communicates back to the sender the size of the buffer whenever it acknowledges a packet. The sender, if it’s respecting the protocol, avoids sending more data that can fit in the receiver’s buffer.
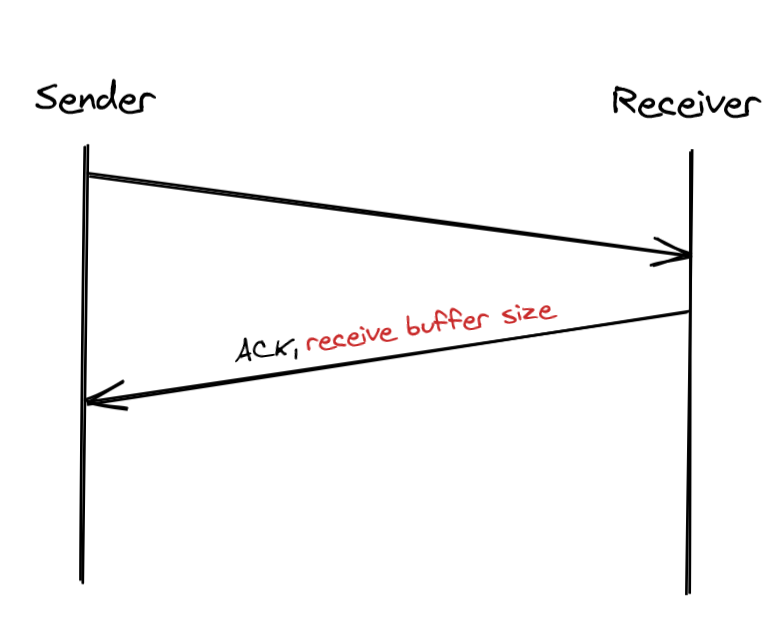
This mechanism is not too dissimilar to rate-limiting at the application level. But, rather than rate limiting on an API key or IP address, TCP is rate-limiting on a connection level.
The lower the round-trip time (RTT) between the sender and the receiver is, the faster the sender adapts its outgoing bandwidth to the receiver’s capacity.
Congestion Control
TCP not only guards against overwhelming the receiver but also against flooding the underlying network.
How can the sender find out what the available bandwidth of the underlying network is? The only way to estimate it is empirically through measurements.
The idea is that the sender maintains a so-called “congestion window.” The window represents the total number of outstanding packets that can be sent without waiting for an acknowledgment from the other side. The size of the receiver window limits the maximum size of the congestion window. The smaller the congestion window is, the fewer bytes can be in flight at any given time, and the less bandwidth is utilized.
When a new connection is established, the size of the congestion window is set to a system default. Then, for every packet acknowledged, the window increases its size exponentially. This means that we can’t use the full capacity of the network right after a connection is established. Once again, the lower the round trip time is, the quicker the sender can start utilizing the underlying network’s bandwidth.
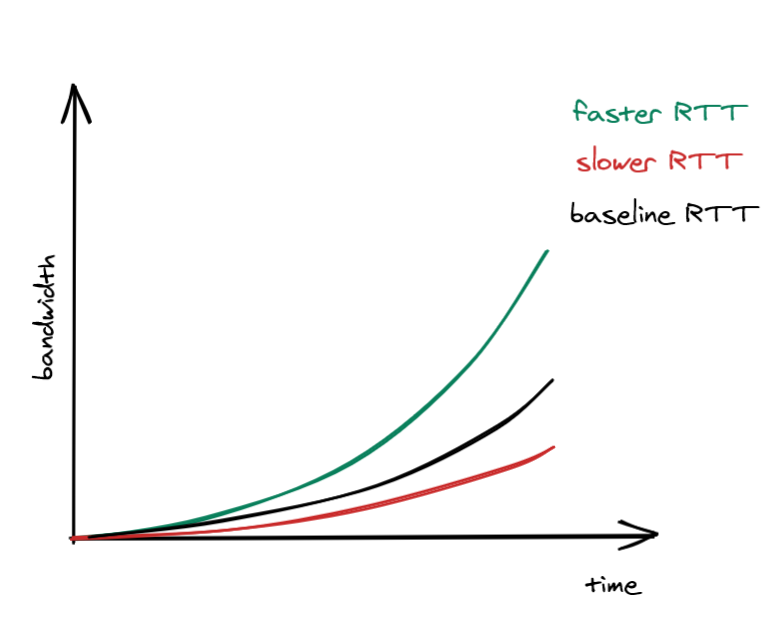
What happens if a packet lost? When the sender detects a missed acknowledgment through a timeout, a mechanism called “congestion avoidance” kicks in, and the congestion window size is reduced. From there onwards, time increases the window size by a certain amount, and timeouts decrease it by another.
As mentioned, the size of the congestion window defines the maximum number of bits that can be sent without waiting for an acknowledgment. The sender needs to wait for a full round trip to get an acknowledgment. So, by dividing the size of the congestion window by the round trip time, we get the maximum theoretical bandwidth:
$$ Bandwidth = \frac{WinSize}{RTT} $$This simple equation shows that bandwidth is a function of latency. TCP will try very hard to optimize the window size since it can’t do anything about the round trip time. But, that doesn’t always yield the optimal configuration.
To summarize, congestion control is an adaptive mechanism used to infer the underlying bandwidth and congestion of the network. A similar pattern can be applied at the application level as well. Think of what happens when you watch a movie on Netflix. It starts blurry; then, it stabilizes to something reasonable until there is a hiccup, and the quality worsens again. This mechanism applied to video streaming is called adaptive bitrate streaming.
Remember this
If you are using HTTP, then you are at the mercy of the underlying protocols. You can’t get the best performance if you don’t know how the sausage is made.
Bursty requests suffer from the cold start penalty. Multiple round trips can be required to send the first byte with TCP and TLS handshakes. And due to the way congestion control works, the lower the round trip time is, the better the underlying network’s bandwidth is utilized.
Entire books have been written on the subject, and there is a lot you can do to squeeze every ounce of bandwidth. But if you have to remember one thing about TCP then let it be this:
You can’t send data faster than the speed of light, but what you can do is put your servers closer to the clients and re-use connections to avoid the cold start penalty.