Differential privacy for dummies
Technology allows companies to collect more data and with more detail about their users than ever before. Sometimes that data is sold to third parties, other times it’s used to improve products and services.
In order to protect users’ privacy, anonymization techniques can be used to strip away any piece of personally identifiable data and let analysts access only what’s strictly necessary. As the Netflix competition in 2007 has shown though, that can go awry. The richness of data allows to identify users through a sometimes surprising combination of variables like the dates on which an individual watched certain movies. A simple join between an anonymized datasets and one of many publicly available, non-anonymized ones, can re-identify anonymized data.
Aggregated data is not much safer either under some circumstances! For example, say we have two summary statistics: one is the number of users, including Frank, that watch one movie per day and the other is the number of users, without Frank, that watch one movie per day. Then, by comparing the counts, we could tell if Frank watches one movie per day.
Differential Privacy to the rescue
Differential privacy formalizes the idea that a query should not reveal whether any one person is present in a dataset, much less what their data are. Imagine two otherwise identical datasets, one with your information in it, and one without it. Differential Privacy ensures that the probability that a query will produce a given result is nearly the same whether it’s conducted on the first or second dataset. The idea is that if an individual’s data doesn’t significantly affect the outcome of a query, then he might be OK in giving his information up as it is unlikely that the information would be tied back to him. The result of the query can damage an individual regardless of his presence in a dataset though. For example, if an analysis on a medical dataset finds a correlation between lung cancer and smoking, then the health insurance cost for a particular smoker might increase regardless of his presence in the study.
More formally, differential privacy requires that the probability of a query producing any given output changes by at most a multiplicative factor when a record (e.g. an individual) is added or removed from the input. The largest multiplicative factor quantifies the amount of privacy difference. This sounds harder than it actually is and the next sections will iterate on the concept with various examples, but first we need to define a few terms.
Dataset
We will think of a dataset $ d $ as being a collection of records from an universe $ U $. One way to represent a dataset $ d $ is with a histogram in which each entry $ d_i $ represents the number of elements in the dataset equal to $ u_i \in U $. For example, say we collected data about coin flips of three individuals, then given the universe $ U = \{head, tail\} $, our dataset $ d $ would have two entries: $ d_{head} = i $ and $ d_{tail} = j $, where $ i + j = 3 $. Note that in reality a dataset is likely to be an ordered lists of rows (i.e. a table) but the former representation makes the math a tad easier.
Distance
Given the previous definition of dataset, we can define the distance between two datasets $ x, y $ with the $ l_1 $ norm as:
$$ \displaystyle ||x - y||_1 = \sum\limits_{i=1}^{|U|} |x_i - y_i| $$Mechanism
A mechanism is an algorithm that takes as input a dataset and returns an output, so it can really be anything, like a number, a statistical model or some aggregate. Using the previous coin-flipping example, if mechanism $ C $ counts the number of individuals in the dataset, then $ C(d) = 3 $. In practice though we will specifically considering randomized mechanisms, where the randomization is used to add privacy protection.
Differential Privacy
A mechanism $ M $ satisfies $ \epsilon $ differential privacy if for every pair of datasets $ x, y $ such that $ ||x - y||_1 \leq 1 $, and for every subset $ S \subseteq \text{Range}(M) $:
$$ \displaystyle \frac{Pr[M(x) \in S]}{Pr[M(y) \in S]} \leq e^{\epsilon} $$What’s important to understand is that the previous statement is just a definition. The definition is not an algorithm, but merely a condition that must be satisfied by a mechanism to claim that it satisfies $ \epsilon $ differential privacy. Differential privacy allows researchers to use a common framework to study algorithms and compare their privacy guarantees.
Let’s check if our mechanism $ C $ satisfies $ 1 $ differential privacy. Can we find a counter-example for which:
$$ \displaystyle \frac{Pr[C(x) \in S]}{Pr[C(y) \in S]} \leq e $$is false? Given $ x, y $ such that $ ||x - y||_1 = 1 $ and $ ||x||_1 = k $, then:
$$ \displaystyle \frac{Pr[C(x) = k]}{Pr[C(y) = k]} \leq e $$i.e. $ \frac{1}{0} \leq e $, which is clearly false, hence this proves that mechanism $ C $ doesn’t satisfy $ 1 $ differential privacy.
Composition theorems
A powerful property of differential privacy is that mechanisms can easily be composed. These require the key assumption that the mechanisms operate independently given the data.
Let $ d $ be a dataset and $ g $ an arbitrary function. Then, the sequential composition theorem asserts that if $ M_I(d) $ is $ \epsilon_i $ differentially private, then $ M(d) = g(M_1(d), M_2(d), ..., M_N(d)) $ is $ \sum_{i=1}^{N}\epsilon_i $ differentially private. Intuitively this means that given an overall fixed privacy budget, the more mechanisms are applied to the same dataset, the more the available privacy budget for each individual mechanism will decrease.
The parallel composition theorem asserts that given $ N $ partitions of a dataset $ d $, if for an arbitrary partition $ d_i $, $ M_i(d_i) $ is $ \epsilon $ differentially private, then $ M(d) = g(M_1(d_1), M_2(d_2), ..., M_N(d_N)) $ is $ \epsilon $ differentially private. In other words, if a set of $ \epsilon $ differentially private mechanisms is applied to a set of disjoint subsets of a dataset, then the combined mechanism is still $ \epsilon $ differentially private.
The randomized response mechanism
The first mechanism we will look into is “randomized response”, a technique developed in the sixties by social scientists to collect data about embarrassing or illegal behavior. The study participants have to answer a yes-no question in secret using the following mechanism $ M_R(d, \alpha, \beta) $:
-
Flip a biased coin with probability of heads $ \alpha $;
-
If heads, then answer truthfully with $ d $;
-
If tails, flip a coin with probability of heads $ \beta $ and answer “yes” for heads and “no” for tails.
In code:
def randomized_response_mechanism(d, alpha, beta):
if random() < alpha:
return d
elif random() < beta:
return 1
else:
return 0
Privacy is guaranteed by the noise added to the answers. For example, when the question refers to some illegal activity, answering “yes” is not incriminating as the answer occurs with a non-negligible probability whether or not it reflects reality, assuming $ \alpha $ and $ \beta $ are tuned properly.
Let’s try to estimate the proportion $ p $ of participants that have answered “yes”. Each participant can be modeled with a Bernoulli variable $ X_i $ which takes a value of 0 for “no” and a value of 1 for “yes”. We know that:
$$ \displaystyle P(X_i = 1) = \alpha p + (1 - \alpha) \beta $$Solving for $ p $ yields:
$$ \displaystyle p = \frac{P(X_i = 1) - (1 - \alpha) \beta}{\alpha} $$Given a sample of size $ n $, we can estimate $ P(X_i = 1) $ with $ \frac{\sum_{i=1}^{i=n} X_i}{n} $. Then, the estimate $ \hat{p} $ of $ p $ is:
$$ \displaystyle \hat{p} = \frac{\frac{\sum\limits_{i=1}^{i=n} X_i}{n} - (1 - \alpha) \beta}{\alpha} $$To determine how accurate our estimate is we will need to compute its standard deviation. Assuming the individual responses $ X_i $ are independent, and using basic properties of the variance,
$$ \displaystyle \mathrm{Var}(\hat{p}) = \mathrm{Var}\biggl({\frac{\sum_{i=1}^{i=n} X_i}{n \alpha}}\biggr) = {\frac{\mathrm{Var}(X_i)}{n \alpha^2}} $$By taking the square root of the variance we can determine the standard deviation of $ \hat{p} $. It follows that the standard deviation $ s $ is proportional to $ \frac{1}{\sqrt{n}} $, since the other factors are not dependent on the number of participants. Multiplying both $ \hat{p} $ and $ s $ by $ n $ yields the estimate of the number of participants that answered “yes” and its relative accuracy expressed in number of participants, which is proportional to $ \sqrt{n} $.
The next step is to determine the level of privacy that the randomized response method guarantees. Let’s pick an arbitrary participant. The dataset $ d $ is represented with either 0 or 1 depending on whether the participant answered truthfully with a “no” or “yes”. Let’s call the two possible configurations of the dataset respectively $ d_{no} $ and $ d_{yes} $. We also know that $ ||d_i - d_j||_1 \leq 1 $ for any $ i, j $. All that’s left to do is to apply the definition of differential privacy to our randomized response mechanism $ M_R(d, \alpha, \beta) $:
$$ \displaystyle \frac{Pr[M_R(d_{i}, \alpha, \beta) = k]}{Pr[M_R(d_{j}, \alpha, \beta) = k]} \leq e^{\epsilon} $$The definition of differential privacy applies to all possible configurations of $ i, j \text{ and } k $, e.g.:
$$ \displaystyle \begin{gathered}\frac{Pr[M_R(d_{yes}, \alpha, \beta) = 1]}{Pr[M_R(d_{no}, \alpha, \beta) = 1]} \leq e^{\epsilon} \\\ln \left( {\frac{\alpha + (1 - \alpha)\beta}{1 - (\alpha + (1 - \alpha)\beta)}} \right) \leq \epsilon \\\ln \left( \frac{\alpha + \beta - \alpha \beta}{1 - (\alpha + \beta - \alpha \beta)} \right) \leq \epsilon\end{gathered} $$The privacy parameter $ \epsilon $ can be tuned by varying $ \alpha \text{ and } \beta $. For example, it can be shown that the randomized response mechanism with $ \alpha = \frac{1}{2} $ and $ \beta = \frac{1}{2} $ satisfies $ \ln{3} $ differential privacy.
The proof applies to a dataset that contains only the data of a single participant, so how does this mechanism scale with multiple participants? It follows from the parallel composition theorem that the combination of $ \epsilon $ differentially private mechanisms applied to the datasets of the individual participants is $ \epsilon $ differentially private as well.
The Laplace mechanism
The Laplace mechanism is used to privatize a numeric query. For simplicity we are going to assume that we are only interested in counting queries $ f $, i.e. queries that count individuals, hence we can make the assumption that adding or removing an individual will affect the result of the query by at most 1.
The way the Laplace mechanism works is by perturbing a counting query $ f $ with noise distributed according to a Laplace distribution centered at 0 with scale $ b = \frac{1}{\epsilon} $,
$$ \displaystyle Lap(x | b) = \frac{1}{2b}e^{- \frac{|x|}{b}} $$Then, the Laplace mechanism is defined as:
$$ \displaystyle M_L(x, f, \epsilon) = f(x) + Z $$where $ Z $ is a random variable drawn from $ Lap(\frac{1}{\epsilon}) $.
In code:
def laplace_mechanism(data, f, eps):
return f(data) + laplace(0, 1.0/eps)
It can be shown that the mechanism preserves $ \epsilon $ differential privacy. Given two datasets $ x, y $ such that $ ||x - y||_1 \leq 1 $ and a function $ f $ which returns a real number from a dataset, let $ p_x $ denote the probability density function of $ M_L(x, f, \epsilon) $ and $ p_y $ the probability density function of $ M_L(y, f, \epsilon) $. Given an arbitrary real point $ k $,
$$ \displaystyle \frac{p_x(k)}{p_y(k)} = \frac{e^{- \epsilon |f(x) - k|}}{e^{- \epsilon |f(y) - k|}} = $$ $$ \displaystyle e^{\epsilon (|f(x) - k| - |f(y) - k|)} \leq $$ $$ \displaystyle e^{\epsilon |f(x) - f(y)|} $$by the triangle inequality. Then,
$$ \displaystyle e^{\epsilon |f(x) - f(y)|} \leq e^\epsilon $$What about the accuracy of the Laplace mechanism? From the cumulative distribution function of the Laplace distribution it follows that if $ Z \sim Lap(b) $, then $ Pr[|Z| \ge t \times b] = e^{-t} $. Hence, let $ k = M_L(x, f, \epsilon) $ and $ \forall \delta \in (0, 1] $:
$$ \displaystyle Pr \left[|f(x) - k| \ge \ln{\left (\frac{1}{\delta} \right)} \times \frac{1}{\epsilon} \right] = $$ $$ \displaystyle Pr \left[|Z| \ge \ln{\left (\frac{1}{\delta} \right)} \times \frac{1}{\epsilon} \right] = \delta $$where $ Z \sim Lap(\frac{1}{\epsilon}) $. The previous equation sets a probalistic bound to the accuracy of the Laplace mechanism that, unlike the randomized response, does not depend on the number of participants $ n $.
Counting queries
The same query can be answered by different mechanisms with the same level of differential privacy. Not all mechanisms are born equally though; performance and accuracy have to be taken into account when deciding which mechanism to pick.
As a concrete example, let’s say there are $ n $ individuals and we want to implement a query that counts how many possess a certain property $ p $. Each individual can be represented with a Bernoulli random variable:
participants = binomial(1, p, n)
We will implement the query using both the randomized response mechanism $ M_R(d, \frac{1}{2}, \frac{1}{2}) $, which we know by now to satisfy $ \ln{3} $ differential privacy, and the Laplace mechanism $ M_L(d, f, \ln{3}) $ which satisfies $ \ln{3} $ differential privacy as well.
def randomized_response_count(data, alpha, beta):
randomized_data = randomized_response_mechanism(data, alpha, beta)
return len(data) * (randomized_data.mean() - (1 - alpha)*beta)/alpha
def laplace_count(data, eps):
return laplace_mechanism(data, np.sum, eps)
r = randomized_response_count(participants, 0.5, 0.5)
l = laplace_count(participants, log(3))
Note that while that while $ M_R $ is applied to each individual response and later combined in a single result, i.e. the estimated count, $ M_L $ is applied directly to the count, which is intuitively why $ M_R $ is noisier than $ M_L $. How much noisier? We can easily simulate the distribution of the accuracy for both mechanisms with:
def randomized_response_accuracy_simulation(data, alpha, beta, n_samples=1000):
return [randomized_response_count(data, alpha, beta) - data.sum()
for _ in range(n_samples)]
def laplace_accuracy_simulation(data, eps, n_samples=1000):
return [laplace_count(data, eps) - data.sum()
for _ in range(n_samples)]
r_d = randomized_response_accuracy_simulation(participants, 0.5, 0.5)
l_d = laplace_accuracy_simulation(participants, log(3))
As mentioned earlier, the accuracy of $ M_R $ grows with the square root of the number of participants:
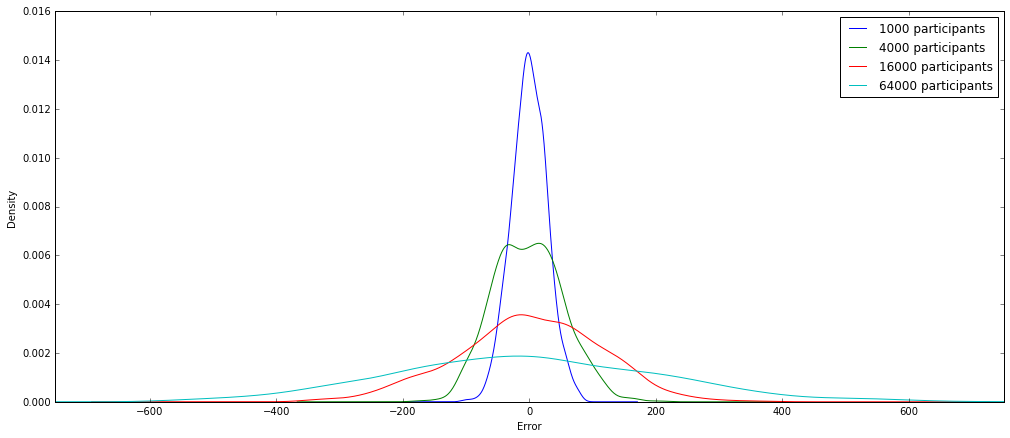
while the accuracy of $ M_L $ is a constant:
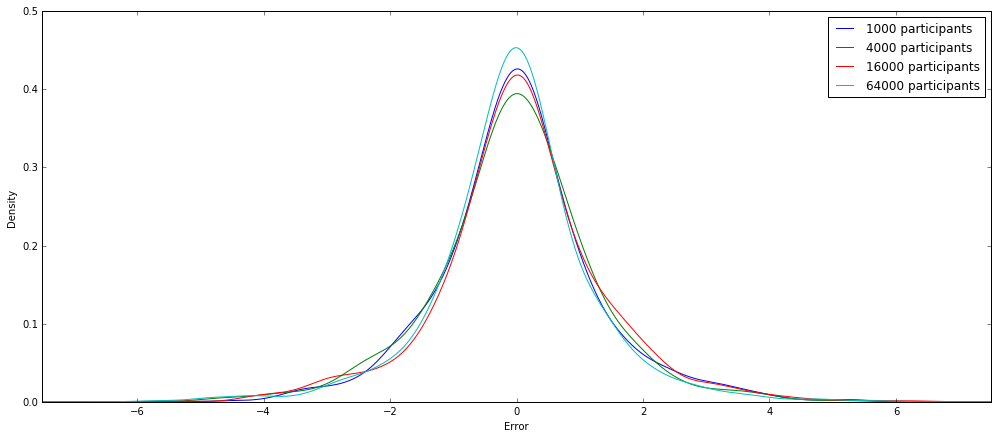
You might wonder why one would use the randomized response mechanism if it’s worse in terms of accuracy compared to the Laplace one. The thing about the Laplace mechanism is that the private data about the users has to be collected and stored, as the noise is applied to the aggregated data. So even with the best of intentions there is the remote possibility that an attacker might get access to it. The randomized response mechanism though applies the noise directly to the individual responses of the users and so only the perturbed responses are collected! With the latter mechanism any individual’s information cannot be learned with certainty, but an aggregator can still infer population statistics.
That said, the choice of mechanism is ultimately a question of which entities to trust. In the medical world, one may trust the data collectors (e.g. researchers), but not the general community who will be accessing the data. Thus one collects the private data in the clear, but then derivatives of it are released on request with protections. However, in the online world, the user is generally looking to protect their data from the data collector itself, and so there is a need to prevent the data collector from ever accumulating the full dataset in the clear.
Real world use-cases
The algorithms presented in this post can be used to answer simple counting queries. There are many more mechanisms out there used to implement complex statistical procedures like machine learning models. The concept behind them is the same though: there is a certain function that needs to be computed over a dataset in a privacy preserving manner and noise is used to mask an individual’s original data values.
One such mechanism is RAPPOR, an approach pioneered by Google to collect frequencies of an arbitrary set of strings. The idea behind it is to collect vectors of bits from users where each bit is perturbed with the randomized response mechanism. The bit-vector might represent a set of binary answers to a group of questions, a value from a known dictionary or, more interestingly, a generic string encoded through a Bloom filter. The bit-vectors are aggregated and the expected count for each bit is computed in a similar way as shown previously in this post. Then, a statistical model is fit to estimate the frequency of a candidate set of known strings. The main drawback with this approach is that it requires a known dictionary.
Later on the approach has been improved to infer the collected strings without the need of a known dictionary at the cost of accuracy and performance. To give you an idea, to estimate a distribution over an unknown dictionary of 6-letter strings without knowing the dictionary, in the worst case, a sample size in the order of 300 million is required; the sample size grows quickly as the length of the strings increases. That said, the mechanism consistently finds the most frequent strings which enable to learn the dominant trends of a population.
Even though the theoretical frontier of differential privacy is expanding quickly there are only a handful implementations out there that, by ensuring privacy without the need for a trusted third party like RAPPOR, suit well the kind of data collection schemes commonly used in the software industry.
References